
Papyrological Publication Platform (P3)
It is increasingly the case that no matter where or in what format scientific information is published, people expect it to appear online. This is true not only for the sciences but also for the humanities. Electronic publications are not limited, however, to traditional scholarly papers and monographs; they also comprise basic scientific data, such as bibliographies, collection information, textual databases, atlases, etc., which are often organized in digital repositories. These two spheres (that of scholarship and of scientific data) are intricately related but in practical terms still quite distinct: distilling core data from scholarship remains a largely manual task and is therefore quite resource-consuming.
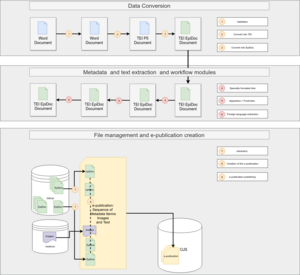
The aim of the P3 initiative, which is a joint undertaking of Heidelberg University’s Institute for Papyrology and University Library, in collaboration with Duke University’s Collaboratory for Classics Computing, funded by the Deutsche Forschungsgemeinschaft, is to bridge scholarly publications and scientific datasets. In its first phase, it focuses on ancient Greek, Latin, and Coptic texts dating from the 3rd c. BCE to the 8th c. CE, which are preserved on papyri and other portable media and come mainly from Egypt. Information pertaining to these texts has for the past several decades been organized in various electronic repositories. Some, such as the Heidelberger Gesamtverzeichnis (HGV), store metadata related to the manuscripts, for example, bibliography and provenance information, while others, such as the Duke Databank of Documentary Papyri (DDbDP), preserve transcripts of the ancient language texts found on papyri. These repositories have been maintained by paid staff and (more recently) by unpaid volunteers who enter by hand information derived from scholarly publications into the relevant electronic resources via the Papyrological Editor at papyri.info.

With P3 and its new e-journal, Pylon, we wish to align the publication and data extraction processes in a semi-automated way. To do this, we have created a transformation tool (available here) that converts word-processing files to TEI/EpiDoc XML, which is one of the main encoding standards in papyrology. When articles containing new editions of papyrological texts are accepted for publication in the e-journal, this tool transforms the word processing file into TEI/EpiDoc XML. The EpiDoc data is, in turn, converted by the University Library to TEI documents that conform to the standards of heiEDITIONS, Heidelberg’s digital editions infrastructure. Information relevant to research data repositories is then fed as TEI/EpiDoc XML into papyri.info, while also being stored in GitHub, where it is openly available to other initiatives that might be interested in using it. This kind of information includes basic metadata concerning the provenance, dating, bibliography, etc. of papyrological texts; ancient language transcriptions; translations and commentaries.
The articles themselves are published digitally in the new, peer-reviewed e-journal called Pylon on Heidelberg’s Propylaeum website.
